Today marks a significant milestone for us at Valantic CEC (formerly known as netz98) as we celebrate five fruitful years of utilizing ddev. Our journey with this remarkable tool has not only streamlined our development processes but also brought about a transformation in how we approach our projects. As we reflect on the past five years, it’s a perfect opportunity to share insights into how ddev has benefited our team, enhanced our workflows, and contributed to our overall success.
A Game Changer in Development
When we first adopted ddev, our development landscape was cluttered and chaotic. Developers struggled to set up their environments consistently, leading to inefficiencies and frustrations. We needed a solution that would simplify our workflow and empower our team to focus on what really matters: delivering high-quality e-commerce solutions for our clients.
ddev emerged as that solution. As a powerful local development environment, it allows developers to quickly spin up and manage complex applications with little configuration required. The ease of use and robust capabilities made it an instant favorite within our team. Our developers can now set up projects with just a few commands, eliminating the days spent wrestling with environment configurations.
Supporting the Community
Our commitment to ddev extends beyond our internal use; we actively support the tool and its community. We maintain the official OpenSearch addon, which enhances ddev’s capabilities and ensures that our development environment is equipped with the latest features. Additionally, we’re proud to provide an n8n addon, allowing for seamless integration of workflows and automation in our projects. You can check it out here: ddev-n8n.
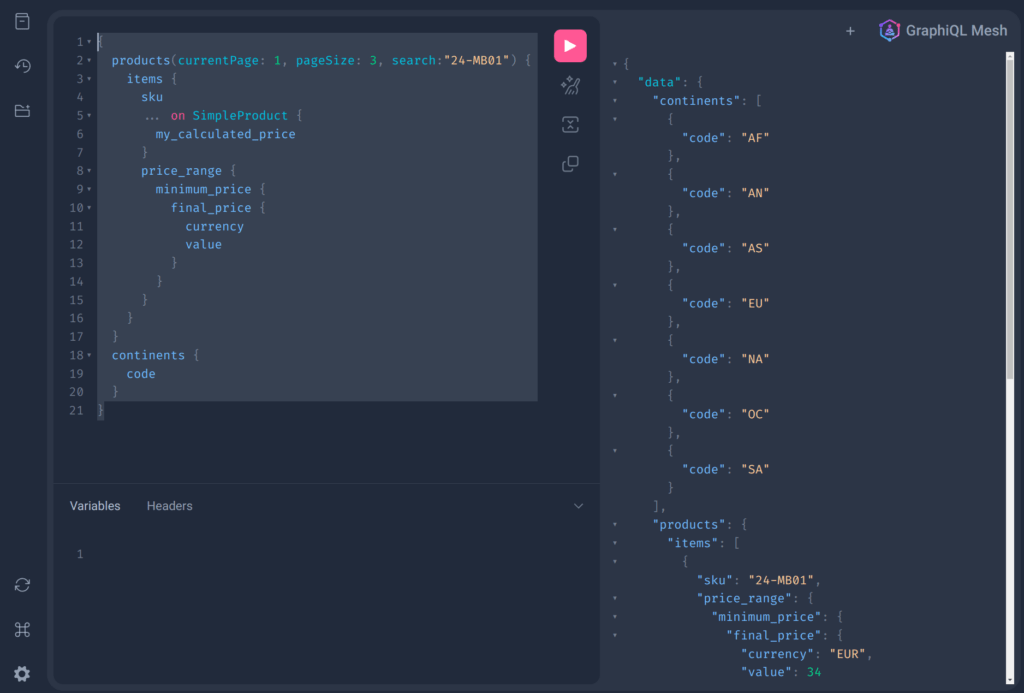
Moreover, our contributions to ddev are not just about the tools we support. Over the years, we have shared our knowledge through various articles and demonstrations, making it easier for other developers to adopt ddev in their own workflows. For instance, our demo setup for Magento Open Source, available at ddev-magento-demo, serves as a valuable resource for those looking to get started with ddev and Magento.
Streamlining Development Processes
One of the most significant impacts of ddev on our organization has been its ability to streamline developer setups. By establishing a standardized development environment, we have drastically reduced onboarding times for new team members. They no longer need to spend hours configuring their local machines; instead, they can dive straight into development. This uniformity not only boosts productivity but also enhances collaboration, as everyone works within the same framework.
Furthermore, the flexibility offered by ddev facilitates the use of numerous services tailored to our clients’ needs. Whether it’s managing databases or running background jobs, our developers can configure the environment to suit the specific demands of a project with ease.
We can easily transfer configurations for several commonly used services between projects. In the meantime, most of the developers are experienced enough to modify or extend the setup.
A Heartfelt Thanks to Randy Fay
As we celebrate our fifth anniversary with ddev, we want to extend our heartfelt congratulations to Randy Fay, the maintainer of this exceptional tool. Your vision and commitment have made ddev a cornerstone of our development processes. Knowing that we have a dedicated maintainer behind ddev gives us confidence in its ongoing evolution. We genuinely appreciate the hard work and dedication that goes into maintaining such a powerful tool.
We also do not forget Stas Zhuk for all the help as Co-Maintainer of the project.
Looking Ahead
As we move forward, we remain excited about the possibilities that ddev presents. The landscape of e-commerce development is constantly evolving, and so are the needs of our clients. Embracing tools like ddev allows us to stay agile, respond to market changes, and ultimately deliver better solutions for our customers.
For those who have yet to explore what ddev can offer, I encourage you to give it a try. Experience the benefits of a streamlined development process, enhanced collaboration, and a supportive community. With ddev in your toolkit, tackling complex e-commerce challenges becomes not just achievable but enjoyable.
In conclusion, let us celebrate not only our past with ddev but also the exciting future ahead. As we continue to leverage its capabilities, we invite you to join us on this journey. Together, we can build efficient, scalable, and powerful e-commerce solutions that empower businesses to thrive in the digital marketplace. Here’s to many more years of innovation and success!
– Creator of n98-magerun
– Fan of football club @wormatia
– Magento user since version 0.8 beta
– 8x certified Magento developer
– PHP Top 1.000 developer (yes, I’m PHP4 certified and sooooo old)
– Chief development officer at netz98